



Uma das maneiras mais simples (e de sucesso) de aprendizagem é a indução por meio de árvores de decisão. Uma árvore de decisão é uma árvore que (i) possui um nó raiz, (ii) cada nó interno tem uma regra que atribui instâncias de treino unicamente aos nós filhos, e (iii) cada nó folha tem um rótulo de classe.
Em outras palavras, cada nó interno testa um atributo, cada ramo corresponde a um valor do atributo e cada folha atribui uma classificação. Tem-se, em geral, como entrada, uma situação descrita por um conjunto de propriedades/atributos e, como saída, uma decisão.
Árvores de decisão são usuais em situações com exemplos (conjunto de treinamento) previamente classificados com regras desconhecidas que se pretendem descobrir/aprender. A partir de um conjunto de propriedades, é decidido sim ou não.
Uma árvore de decisão pode descrever qualquer função booleana. Na Figura 1, é exemplificado o uso de uma árvore de decisão (à esquerda) para a função booleana OU (tabela-verdade à direita).
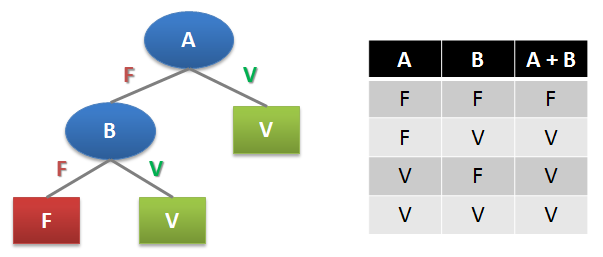
Uma vez construída uma árvore de decisão, seu uso é imediato e computacionalmente rápido. Entretanto, sua construção pode ser uma tarefa de muita demanda computacional.
A partir de um conjunto de atributos, uma árvore de decisão poder ser estruturada de diversas maneiras. Uma vez que o número de árvores de decisão possíveis cresce bastante à medida que o número de atributos aumenta, torna-se impraticável buscar a estrutura da árvore de decisão ótima para um determinado problema, devido ao elevado custo computacional envolvido (problema NP-Completo). Nesse sentido, há algoritmos baseados em heurísticas que, mesmo não garantindo uma solução ótima, apresentam resultados aceitáveis.
O algoritmo pioneiro em indução por árvores de decisão é o ID3 (inductive decision tree), algoritmo recursivo baseado em busca gulosa, procurando, em um conjunto de atributos, aqueles que melhor dividem os exemplos, gerando sub-árvores. A ideia é testar o atributo mais importante (que faz a maior diferença para a classificação de um exemplo) para obter a classificação correta com um pequeno número de testes (caminhos curtos e, consequentemente, árvore pequena).
Os passos do algoritmo ID3 são os seguintes:
Começar com todos os exemplos do conjunto de treinamento;
Escolher o atributo que melhor agrupe exemplos da mesma classe ou exemplos semelhantes;
Para o atributo escolhido, criar um nó filho para cada valor possível do atributo;
Para cada nó filho criado, transportar os exemplos do nó pai de acordo com o teste;
Repetir o procedimento para cada filho não "puro" (um filho é puro quando cada atributo tem o mesmo valor em todos os exemplos).
Para selecionar o melhor atributo, as medidas mais usadas são a Entropia, o Coeficiente de Gini e o Erro de Classificação. Seja p(c|t) a probabilidade condicional da classe c no nó t, as medidas são dadas a seguir.
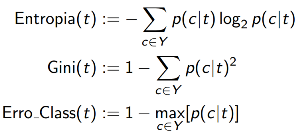
O Coeficiente de Gini e o Erro de Classificação são medidas que variam de 0 a 0,5. A Entropia varia de 0 a 1. Quanto maior o valor, maior o grau de impureza do conjunto. Dessa forma, essas medidas terão valor 0 quando todos os elementos forem da mesma classe e, por outro lado, terão valor máximo (1 no caso da Entropia e 0,5 no Coeficiente de Gini e no Erro de Classificação) quando os elementos forem distribuídos igualmente nas classes.
Um exemplo de cálculo dessas medidas pode ser visto abaixo, no qual foram consideradas 6 instâncias.

Para verificar a qualidade da partição, compara-se os graus de impureza do nó pai (antes da partição) com os dos nós filhos (depois da partição) quanto maior a diferença, melhor. Para essa verificação, pode-se usar o critério denominado Ganho, formulado abaixo.

Para exemplificar como utilizar esses conceitos, considere os dados da tabela abaixo (dados de treinamento) de uma linha de montagem com vários sensores. Para identificar quais peças devem ser rejeitadas por serem muito frágeis, pretende-se usar aprendizagem por árvores de decisão.
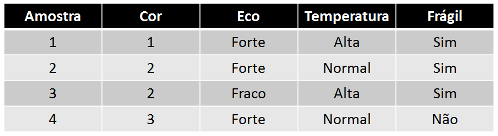
Usando a medida de Entropia, tem-se os seguintes cálculos:
Entropia = -(3/4)*(log2(3/4)) - (1/4)*(log2(1/4)) = 0,811
Ganho(Temperatura) = 0,811 - (2/4)*EntropiaDeTemperaturaAlta - (2/4)*EntropiaDeTemperaturaNormal
Ganho(Eco) = 0,811 - (3/4)*EntropiaDeEcoForte - (1/4)*EntropiaDeEcoFraco
Ganho(Cor) = 0,811 - (1/4)*EntropiaDeCor1 - (2/4)*EntropiaDeCor2 - (1/4)*EntropiaDeCor3
EntropiaDeTemperaturaAlta = 0 (todos os elementos com temperatura alta são frágeis)
EntropiaDeTemperaturaNormal = 1 (dos dois elementos com temperatura normal, um é frágil e outro não)
EntropiaDeEcoForte = -(1/3)*(log2(1/3)) - (2/3)*(log2(2/3)) = 0.9183
EntropiaDeEcoFraco = 0 (todos os elementos de eco fraco são frágeis)
EntropiaDeCor1 = 0 (todos os elementos de cor 1 são frágeis)
EntropiaDeCor2 = 0 (todos os elementos de cor 2 são frágeis)
EntropiaDeCor3 = 0 (todos os elementos de cor 3 não são frágeis)
Ganho(Temperatura) = 0,811 - (2/4)*0 - (2/4)*1 = 0,811 - (2/4) = 0.311
Ganho(Eco) = 0,811 - (3/4)*0.9183 - (1/4)*0 = 0,811 - (3/4)*0.9183 = 0.122275
Ganho(Cor) = 0,811 - (1/4)*0 - (2/4)*0 - (1/4)*0 = 0,811
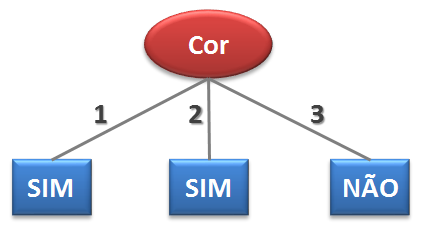
O atributo com o maior Ganho é escolhido (no caso, Cor). Tendo em vista que o Ganho com esse atributo (0,811) é igual ao valor da Entropia (0,811), a escolha desse atributo (e, consequentemente, seu teste) já possibilita classificar os elementos do conjunto de treinamento como frágeis ou não. No caso, a árvore de decisão para esse problema pode ser a ilustrada na Figura 2.
Árvores de decisão apresentam algumas limitações. As árvores memorizam as observações, não extraindo padrões dos exemplos e, assim, não se espera muito que sua aptidão extrapole para exemplos não previstos. Em síntese, não existe um tipo de representação eficiente para todos os tipos de funções.
Para mais detalhes sobre árvores de decisão, você pode consultar as referências abaixo.
-----
Referências:
FECHINE, Joseana Macêdo. Inteligência Artificial I - Aprendizagem (Parte II), disponível em http://dsc.ufcg.edu.br/~joseana/IA_NA19.zip, acesso em 6 de outubro de 2012.______. Inteligência Artificial I - Aprendizagem (Parte II - Exemplo), disponível em http://dsc.ufcg.edu.br/~joseana/IA_NA19Exemplo.zip, acesso em 6 de outubro de 2012.
MARINHO, L. B. Macêdo. Árvores de Decisão, disponível em http://dsc.ufcg.edu.br/~lbmarinho/slides/ia_2012_2/arvore_decisao.pdf, acesso em 8 de outubro de 2012.
ZUBEN, F. J. V. & ATTUX, R. R. F. Árvores de Decisão, disponível em ftp://ftp.dca.fee.unicamp.br/pub/docs/vonzuben/ia004_1s10/notas_de_aula/topico7_IA004_1s10.pdf, acesso em 10 de outubro de 2012.
Grupo PET Computação UFCG, 2012. All rights reserved.
