



Muitos algoritmos agem baseados em cálculos e comparações de algum tipo de similaridade (ou dissimilaridade) entre instâncias/atributos dos dados. A similaridade mede o quanto duas instâncias são parecidas: quanto mais parecidas, maior o valor. Geralmente, esse valor pertence ao intervalo [0, 1]. Analogamente, dissimilaridade mede o quanto dois objetos são diferentes. Converter dissimilaridades em similaridades, e vice-versa, é muitas vezes útil e permite tratar tudo de uma só forma.
Em geral, problemas de mineração de dados envolvem apenas atributos numéricos, mas é possível transformar atributos categóricos em numéricos para aplicar ferramentas de mineração de dados que lidam exclusivamente com esse tipo de atributo.
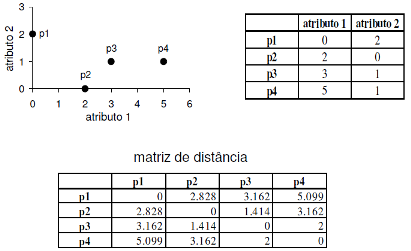
Para duas instâncias descritas por um conjunto de n atributos numéricos, a maneira mais comum de se medir (dis)similaridade entre elas é o uso de uma medida de distância, sendo a medida de distância Euclidiana a mais popular (cálculo mostrado abaixo).

Em geral, seja s(p, q) a similaridade entre duas instâncias p e q, s(p, q) é igual a 1 apenas se p for igual a q (similaridade máxima).
Além disso, s(p, q) é igual a s(q, p). Comumente, instâncias p e q são descritas apenas por atributos binários e as similaridades podem ser computadas usando o seguinte:
Um exemplo do uso da distância Euclidiana é apresentado abaixo.
Em geral, seja s(p, q) a similaridade entre duas instâncias p e q, s(p, q) é igual a 1 apenas se p for igual a q (similaridade máxima). Além disso, s(p, q) é igual a s(q, p). Comumente, instâncias p e q são descritas apenas por atributos binários e as similaridades podem ser computadas usando o seguinte:

Em relação à similaridade com atributos binários, existem o Coeficiente de Casamento Simples e o Coeficiente Jaccard. O Coeficiente de Casamento Simples conta igualmente o número de ocorrências de 1 (um) e 0 (zero); portanto, é adequado quando ambos os valores são realmente equivalentes (atributos binários simétricos). O Coeficiente Jaccard não considera as coincidências de números 0 (zero), para lidar adequadamente com atributos assimétricos, uma vez que os números 0 (zero) indicam apenas ausência de uma característica e, no caso, a similaridade se dá pelas características presentes. As fórmulas e um exemplo de cálculo para esses coeficientes podem ser vistos a seguir.

Outra medida de similaridade bastante utilizada, especialmente em Sistemas de Recomendação, é a medida do Cosseno. A ideia é usar o ângulo entre dois vetores como medida de similaridade. A similaridade é máxima quando os vetores apontam na mesma direção (ângulo = 0º), e mínima quando são perpendiculares (ângulo = 90º).

Além das medidas de similaridade mencionadas nesta matéria, há outras também bastante utilizadas, como o Coeficiente de Pearson (ou Correlação), que diferente das apresentadas, contempla o intervalo [-1, 1]. Para mais detalhes das medidas aqui apresentadas e de outras, você pode consultar as referências abaixo.
-----
Referências:
CAMPELLO, R. J. G. B. SCC0173 Mineração de Dados Biológicos - Preparação de Dados: Parte B, disponível em http://wiki.icmc.usp.br/images/e/e1/Preparacao_Dados_II.pdf, acesso em 12 de novembro de 2012.
MARINHO, L. B. Algoritmo dos Vizinhos mais Próximos, disponível em http://dsc.ufcg.edu.br/~lbmarinho/slides/ia_2012_2/vizinhos.pdf, acesso em 12 de novembro de 2012.
Grupo PET Computação UFCG, 2012. All rights reserved.
