



Resolução de Entidades (RE), também conhecida como Entity Matching, deduplication, ou record linkage, é a tarefa de identificar entidades (e.g., pessoas, produtos, publicações, websites, entre outros) que se referem a um mesmo objeto do mundo real [1]. É uma tarefa de extrema importância para as áreas de limpeza e integração de dados (e.g., encontrar descrições de produtos duplicados em uma ou mais fontes de dados). Porém, junto com sua importância vem seus problemas. RE é uma tarefa intensiva em dados quando processada em grandes volumes de dados. Trata-se de um problema crítico em termos de desempenho devido ao alto custo computacional necessário para processar conjuntos de dados grandes. Por isso, são necessários estudos que objetivem descobrir como a RE pode se beneficiar da computação distribuída.
Nos últimos anos, temos visto um avanço enorme na pesquisa de RE no domínio de Ciência da Computação, especialmente em áreas como Data Mining, Aprendizado de Máquina, Recuperação da Informação, Banco de Dados e Comunidades de Data Warehouse. À medida que as fontes de dados geradas pelas organizações vão aumentando e a qualidade dos dados vai sendo reconhecida com uma das maiores dificuldades para se utilizar essas fontes, a tarefa de identificar as entidades duplicadas em fontes de dados, heterogêneas ou não, tem se tornado mais pervasiva do que nunca. Várias técnicas de RE tem sido propostas para aplicar abordagens sofisticadas de aprendizado de máquina, processamento de linguagem natural e grafos. Essas técnicas aprimoraram tanto a qualidade quanto tempo de execução da detecção de similaridades em grandes fontes de dados que contém milhões de entidades.
Apesar dos avanços, devido às enormes proporções que as fontes de dados têm alcançado nos últimos tempos, as técnicas elaboradas ao longo destes quarenta anos (sem levar em conta mecanismos de paralelização), e.g. técnicas de blocagem, tornaram-se ineficientes em termos de tempo de execução. No contexto atual, não há mais interesse que um processo de RE seja executado durante vários dias. Para superar essa ineficiência, a comunidade científica tem dado ênfase na utilização de computação distribuída para procesar tarefas de RE propondo abordagens distribuídas que refletem o mesmo comportamento das técnicas já consolidadas (e.g., RE baseado em blocagem).
A solução é propor abordagens distribuídas aprimoradas para executar a tarefa de RE em curto espaço de tempo.
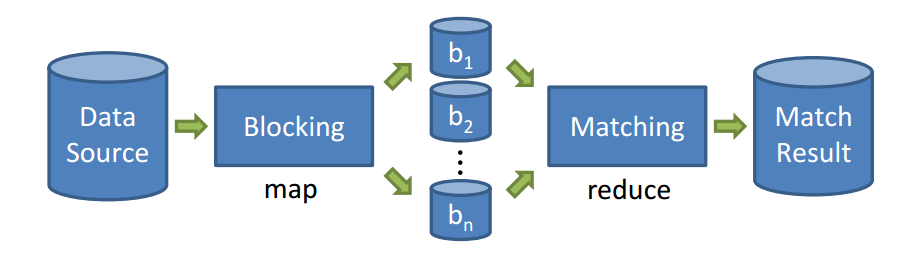
Até o momento, contemplamos o método de blocagem Standard Blocking [4] (o mais comum), os próximos passos será propor novas abordagens para os demais métodos de blocagem, e.g., Sorted Neighborhood, fuzzy blocking e clustering [4].
Os integrantes do projeto são: o mestrando Demetrio Gomes Mestre, Orientador: Prof. Carlos Eduardo.
O projeto do Doutorado deve seguir algo próximo dessa linha e talvez haja a participação de outro doutorando e um mestrando também recém-aprovado.
Em 2013, foi publicado um artigo envolvendo a abordagem BlockSlicer no 18o IEEE symposium on computers and communications (ISCC13) (Qualis A2) [2] e tambem um artigo resumido no 28o Simpósio Brasileiro de Banco de Dados (SBBD13) envolvendo a abordagem MSBlockSlicer [3] (expansão do BlockSlicer para contemplar o problema de RE que envolve múltiplas fontes de dados). O artigo resumido foi selecionado como um dos seis melhores do SBBD13 (entre os artigos resumidos) e os autores foram convidados a submeter uma versão estendida a ser publicada na edição especial de fevereiro de 2014 no periódico Journal of Information and Data Management (JIDM) (Qualis B3).
[1] Hanna Kopcke and Erhard Rahm. Frameworks for entity matching: A comparison. Data Knowl. Eng., 69(2):197210, February 2010.
[2] Demetrio Gomes Mestre and Carlos Eduardo Pires. Efficient entity matching over multiple data sources with mapreduce. In Proceedings of the 28th Brazilian Symposium on Databases, SBBD13, pages 1924. SBC, 2013.
[3] Demetrio Gomes Mestre and Carlos Eduardo Pires. Improving load balancing for mapreduce-based entity matching. In Proceedings of the Eighteenth IEEE Symposium on Computers and Communications, ISCC 13. IEEE Computer Society, 2013.
[4] Rohan Baxter, Peter Christen, and Tim Churches. A comparison of fast blocking methods for record linkage. In ACM SIGKDD 03 Workshop on Data Cleaning, Record Linkage, and Object Consolidation, pages 2527, 2003.
Editor: Eder Andrade.
Grupo PET Computação UFCG, 2013. All rights reserved.
