Esquema de banco de dados e mapeamento OO-Relacional
Referências
- Há uma discussão detalhada de como tratar persistência de objetos de várias formas
nos livros:
- Object-Oriented Modeling and Design for Database Applications, Blaha e
Premerlani, Prentice Hall, 1998.
- Database Design for Smarties, Muller, Morgan Kaufmann Publishers, 1999.
- Este livro também cobre o mapeamento para SGBDs Objeto-Relacionais
- Nossa discussão é um breve resumo do material desses dois livros
- Um tratamento completo não pode ser dado nesta disciplina devido a restrições de
tempo
- Também tem uma breve discussão de como montar um framework de persistência no livro:
- Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design,
Larman, Prentice-Hall, 1998.
- Frameworks profissionais de persistência podem ser vistos nos produtos TopLink e CocoBase
- Falaremos especialmente do mapeamento de um modelo OO para um esquema relacional
- Não há tempo para tratar do mapeamento para SGBDs Objeto-Relacionais
- Supõe-se uma certa familiaridade com o modelo relacional
Resumo da seção
- Em SGBDOOs, objetos possuem identidade baseada na existência,
mas isso não é automático num SGBDR
- Com um SGBDR (ou quando usam-se arquivos para a persistência), pode-se usar uma de duas
alternativas:
- Identidade baseada na existência
- O SGBDR gera um identificador único (OID) para cada registro
- O OID é armazenado numa coluna adicional e é a chave primária
da tabela
- Identidade baseada em valor
- Uma combinação de atributos identifica cada registro
- As duas alternativas podem ser misturadas num mesmo esquema
- Vantagens da identidade baseada na
existência
- A chave primária é um atributo único, pequeno e uniforme em
tamanho
- Algumas tabelas não possuem uma combinação de atributos que
possa ser chave primária
- Desvantagens da identidade baseada na
existência
- Alguns SGBDs poderão não oferecer a geração de identificadores
únicos
- A geração de identificadores únicos pode necessitar de acesso a
dados globais, interferindo assim com o controle de concorrência e deixando a aplicação
potencialmente mais lenta
- Pode complicar a depuração das aplicações
- Já que os OIDs não possuem semântica em nível de aplicação
- Vantagens da identidade baseada em
valor
- As chaves primárias possuem semântica clara em nível de
aplicação, facilitando a depuração e manutenção do BD
- A distribuição do BD pode ser mais fácil
- Porque não há geração centralizada de identidade
- Mas manter a unicidade das chaves pode não ser simples
- Desvantagens da identidade baseada em
valor
- Chaves primárias podem ser mais difíceis de alterar
- Devido à propagação causada por chaves estrangeiras usadas em
associações e herança
- A propagação poderá não ser suportada automaticamente pelo
SGBD
- Recomendações
- Usar identidade baseada na existência para esquemas maiores (com
mais de 30 classes)
- Não precisa incluir o OID como atributo no modelo UML
- Caso contrário, para aplicações pequenas, considere utilizar a
identidade baseada em valor, ou uma combinação das duas técnicas
- No modelo UML, acrescente o tag {OID} para os atributos que
participam da chave primária
- Há quem recomende usar identidade baseada na existência sempre
CREATE TABLE Pessoa (
EstadoCivil CHARACTER(1) NULL CHECK (EstadoCivil IN ('S', 'C', 'D', 'V'))
...
)
- Codificação da enumeração: como acima, mas usando
inteiros em vez de strings
- Uma tabela pode fornecer o mapeamento entre inteiros e strings correspondentes
- Vantagens:
- Mais fácil lidar com múltiplas línguas
- Usam menos espaço em disco
- Desvantagem (séria)
- Complica a depuração e manutenção (devido ao uso de "números mágicos"
sem semântica própria)
- Um flag por valor de enumeração: use um atributo booleano
para cada valor de enumeração
- Funciona bem apenas quando múltiplos valores podem ser aplicáveis (atributos não
mutuamente exclusivos)
- Exemplo:
CREATE TABLE xxx (
Vermelho CHARACTER(1) NULL
Azul CHARACTER(1) NULL
Amarelo CHARACTER(1) NULL
...
)
- Uma tabela de enumeração: os valores possíveis para a
enumeração são armazenados numa tabela à parte
- Pode haver uma tabela por enumeração ou uma tabela para todas as enumerações
- O código de aplicação verifica que o valor do atributo pertence à tabela
- Boa solução quando há muitos valores
- Vantagem de ter os valores possíveis no próprio BD em vez de tê-los no código
- Novos valores podem ser inseridos facilmente, sem modificar o código
- Mas tabelas adicionais complicam o esquema e o código genérico de manipulação
- Para pequenas enumerações, é mais fácil usar strings e um constraint em SQL
- Use quando há muitos valores ou valores desconhecidos durante o desenvolvimento
- Exemplo:
CREATE TABLE TipoEstadoCivil (
Valor CHAR(1) PRIMARY KEY,
DisplayString VARCHAR2(50) NOT NULL,
Descricao VARCHAR2(2000));
INSERT INTO TipoEstadoCivil (Valor, DisplayString)
VALUES ('S', 'Solteiro');
INSERT INTO TipoEstadoCivil (Valor, DisplayString)
VALUES ('C', 'Casado');
INSERT INTO TipoEstadoCivil (Valor, DisplayString)
VALUES ('D', 'Divorciado');
INSERT INTO TipoEstadoCivil (Valor, DisplayString)
VALUES ('V', 'Viuvo');
)
CREATE TABLE Pessoa (
EstadoCivil CHARACTER(1) NOT NULL DEFAULT 'U'
REFERENCES TipoEstadoCivil(Valor),
...
)
- Para domains estruturados, há três
alternativas, todas válidas em certas situações
- Concatenação: jogue fora a estrutura e armazene o
atributo como string
- Exemplo
- Uma Pessoa tem um Endereço
- O Endereço é um domain estruturado (possui vários atributos)
- Armazene o endereço inteiro como string
- Múltiplas colunas
- O Endereço seria armazenado na tabela Pessoa em colunas diferentes
- Tabela separada
- Pessoa referencia um registro da tabela Endereço
- Para domains multivalorados, use as técnicas de domains
estruturados
- Não há suporte especial do modelo relacional, porque domains multivalorados não
obedecem a primeira forma normal
- No modelo de projeto, algumas classes são persistentes e outras não
- As classes persistentes têm o estereótipo UML «persistent»
- Tratamos aqui apenas das classes persistentes
- As demais definem um comportamento transiente que deve ser tratado no código da
aplicação
- Uma classe contém atributos e operações
- Discutiremos o que fazer com as operações na próxima subseção
- De forma geral, cada classe persistente se transforma numa tabela
e cada atributo se transforma numa coluna da tabela
- Para cada tabela, trata-se a questão de identidade vista acima
- Para cada atributo, trata-se a questão de domains vista acima
- O modelo relacional não trata a visibilidade dos atributos
- Todos os atributos são públicos
- Para atributos que têm tag UML {OID}, use um constraint PRIMARY
KEY
- Para atributos que têm tag UML {alternate OID} (alternate key), use um constraint UNIQUE
- Para atributos que têm tag UML {nullable}, não use o constraint NOT
NULL, caso contrário, use NOT NULL
- Alguns SGBDs permitem que você use o constraint NULL que não faz parte do padrão ANSI
na definição de colunas
- Um SGBD Relacional não permite encapsular operações (métodos) com classes
- Por outro lado, stored procedures são possíveis, o que permite colocar alguma
funcionalidade dos métodos dos objetos da aplicação no SGBD
- Alguns SGBDs oferecem também stored functions que retornam valor
- A questão básica é: "Que tipo de funcionalidade pode ser
adequadamente colocada em stored procedures?"
- No final das contas, podemos particionar o código entre o
servidor de BD e as outras camadas (middle tier, cliente)
- O que é melhor colocar no SGBD e o que é melhor deixar fora?
- Algumas regras sobre o que evitar seguem:
- Não se pode colocar operações que lidam com aspectos transientes no SGBD
- O código de stored procedures não pode acessar os objetos que estão em memória nas
outras camadas
- Não se deve usar stored procedures para acessar dados atributo por atributo
- Um SGBDR acessa dados naturalmente por registro, não por atributo individual
- O acesso ao BD atributo por atributo resultaria numa aplicação muito lenta
- Evite stored procedures que tenham que deixar "estado transiente" armazenado
no BD para fazer outras operações subsequentes (não armazenar estado comportamental
usado entre chamadas)
- Embora alguns SGBDs (Oracle, por exemplo) permitam que isso seja feito, é melhor que
cada chamada a um stored procedure seja reentrante e não dependa de estado
- O sistema resultante é muito mais simples e fácil de manter e depurar
- Tal tipo de estado deve ser mantido na camada do meio (aplicação)
- Evite fazer grandes quantidades de verificação de erro, com condições de aborto,
etc. no SGBD. Mantenha isso em outra camada (aplicação ou cliente)
- Algumas operações de alto desempenho poderão ser mais rápidas quando executadas numa
linguagem compilada (em outra camada), em vez de uma linguagem interpretada para executar
stored procedures (como PL/SQL do Oracle, Transact/SQL do SQLServer)
- Evite fazer ações transacionais (COMMIT, ROLLBACK) em stored procedures
- Faça isso em outra camada
- A semântica de transação é expressa melhor na aplicação em si
- Seria ruim um programador chamar um stored procedure e, depois, ao verificar um erro e
tentar fazer um ROLLBACK, descobrir que a transação já sofreu COMMIT
- O que pode ser colocado no SGBD como stored
procedures?
- Fazer uma consulta dando um result set (um conjunto de registros)
- Insert/update/delete, mas apenas de registros inteiros, não atributo por atributo
- Verificação de regras de consistência e outros business rules
- Talvez este seja o motivo principal do uso de Stored Procedures
- Triggers podem ser valiosos aqui também
- Operações que chamam outros stored procedures (para acessar o dicionário, por
exemplo)
- Verificação de erros (mas apenas erros relacionados com a estrutura do BD)
- Como tratar polimorfismo?
- Ao usar um SGBDR, não há suporte a polimorfismo
- Mesmo SGBDORs têm suporte fraco ou inexistente a polimorfismo
- Evite-o portanto, nas classes persistentes
- Pode usar em classes transientes
- Se o polimorfismo for usado na modelagem de classes persistentes, ele tem que ser
transformado em if-then-else e chamadas as stored procedures diferentes
- Todas essas restrições explicam porque se fala do impedance
mismatch!
- Associações simples são:
- 1-para-1
- 0..1-para-1
- 1-para-muitos
- muitos-para-muitos
- Descrevemos mapeamentos recomendados, alternativos
e desencorajados para cada tipo
- Sempre considere primeiro o mapeamento recomendado
- Mapeamentos alternativos podem ser usados por uma questão de desempenho,
extensibilidade, ou estilo
Associações 1-para-1
- Recomendado
- Embutir a chave estrangeira em qualquer uma das classes
- A chave estrangeira poderá ser nula se houver uma cardinalidade mínima de 0 no alvo
- Alternativo
- A associação pode ser implementada numa tabela à parte
- A chave primária da tabela de associação pode ser qualquer uma das duas chaves
estrangeiras
- Vantagem: o esquema é mais extensível
- Se houver mudança na cardinalidade da associação, basta mudar o constraint, não a
estrutura de tabelas
- Desvantagens: fragmentação do esquema e maior overhead de navegação (com joins)
- Desencorajado
- Combinação: não junte duas classes e sua associação numa
única tabela
- O esquema é mais fácil de entender se seguir o modelo de objetos
- Associações bi-direcionais: não coloque duas chaves estrangeiras, uma em cada tabela
referenciando a outra
- Os SGBDs não vão manter a consistência das associações redundantes
Associações 0..1-para-1
- Recomendado
- Embutir a chave estrangeira na classe com a cardinalidade 0..1
- A chave estrangeira é NOT NULL
Associações 1-para-muitos
- Recomendado
- Embutir a chave estrangeira na classe com cardinalidade "muitos"
- Se a cardinalidade 1 (do alvo) puder ser 0-1, a chave estrangeira pode se nula
- Exemplo:
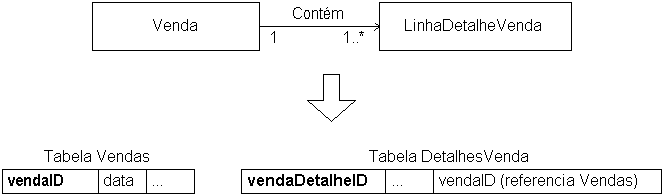
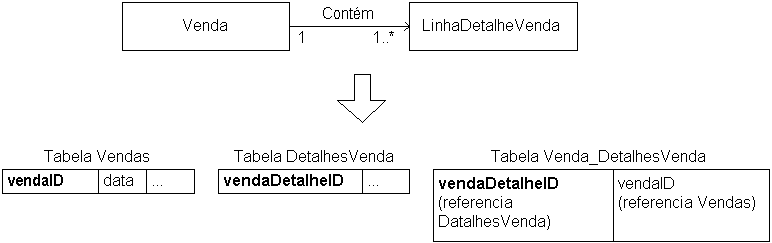
- Alternativo
- A associação pode ser implementada numa tabela à parte
- A chave estrangeira para a classe "muitos" é a chave primária da tabela de
associação
- Mesmas vantagens e desvantagens do mapeamento 1-para-1
- Exemplo:
Associações muitos-para-muitos
- Recomendado
- A associação é mapeada para uma tabela distinta
- A chave primária da tabela de associação é uma combinação das chaves estrangeiras
- Exemplo:
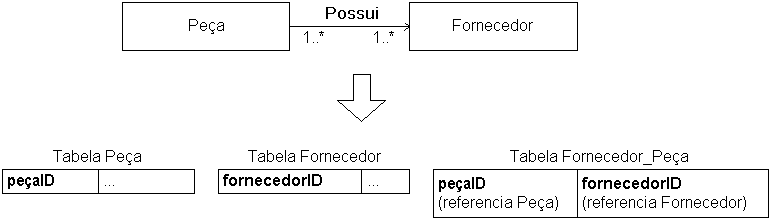
- Associações avançadas são:
- Associação qualificada
- Classe de associação
- Associação ordenada
- Associação ternária
Associação qualificada
- Lembre que uma associação qualificada é uma associação "para-muitos" onde
os objetos envolvidos do lado "muitos" são total ou parcialmente especificados
usando um atributo chamado o qualificador
- Tais associações aumentam a precisão do modelo
- Um qualificador seleciona um ou mais dentre vários
objetos-alvo, com o efeito de reduzir a cardinalidade, às vezes até 1
- Quando a cardinalidade final é 1, a associação qualificada especifica uma forma
precisa de selecionar o objeto alvo a partir do objeto fonte
- Exemplo:
- Uma descrição de vôo se aplica a muitos vôos
- A combinação de uma descrição de vôo mais uma data de partida especifica um vôo
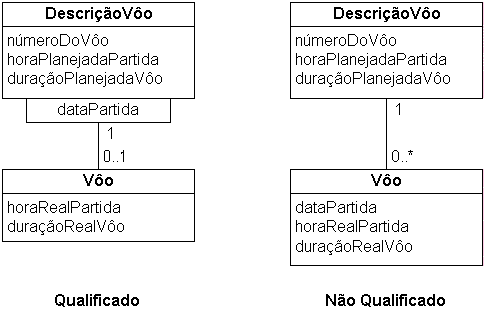
- Recomendado
- O mapeamento é tal qual para a associação sem qualificador
- No exemplo acima, uma chave estrangeira seria incluída na classe Vôo
Classe de associação
- É uma associação com uma classe que a descreve
- A classe de associação pode participar de outras associações
- Recomendado
- Implemente a associação com uma tabela distinta
- A chave primária da classe de associação é uma combinação das chaves primárias
das classes envolvidas na associação
- Exemplo:
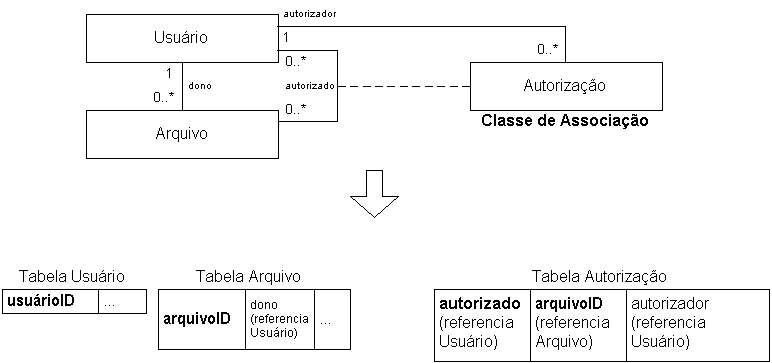
Associação ordenada
- Ocorre quando as ligações entre objetos possuem uma ordem
- Exemplo: janelas podem estar ordenadas numa tela (indicando qual está na frente das
outras)
- O tag UML {ordered} é usado na associação ( ou {ordered by ...})
- Recomendado
- Introduzir um número de sequência como atributo
Associação ternária
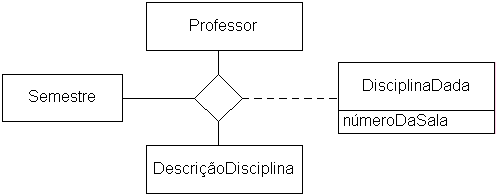
- Recomendado
- Uma tabela distinta deve ser usada para representar a associação ternária
Agregações
- Recomendado
- Agregações são associações e são implementadas como tal
- Recomendado
- Normalmente, a herança é implementada com tabelas separadas para a superclasse e cada
subclasse
- Idealmente, um objeto tem a mesma chave primária na hierarquia inteira
- A superclasse inclui um discriminador que indica qual subclasse se aplica
- Isso não é mostrado no modelo de objetos
- A integridade referencial pode ser usada para garantir que um registro da superclasse
exista para cada registro de uma subclasse
- Entretanto, se a superclasse for abstrata e exigir que haja um objeto de uma subclasse,
a integridade referencial não pode solucionar o problema
- O código da aplicação deve implementar a restrição
- Exemplo:
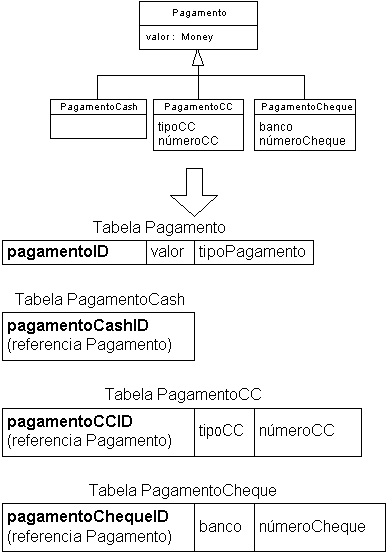
- Pode-se usar uma View para cada subclasse, no sentido de consolidar os dados herdados e
facilitar o acesso ao objeto
- Exemplo:
CREATE VIEW view_PagamentoCC AS
SELECT pagamentoID, valor, tipoCC, numeroCC
FROM Pagamento AS P JOIN PagamentoCC as CC
ON P.pagamentoID = CC.pagamentoCCID
- Alternativo
- Eliminação
- Como otimização, subclasses que não contêm atributos, fora a chave estrangeira,
podem ser eliminadas
- Desvantagens
- O código de navegação tem que saber se há uma tabela ou não para implementar a
subclasse
- Falta de extensibilidade: se houver uma adição à subclasse, a tabela vai ter que
voltar
- Exemplo:
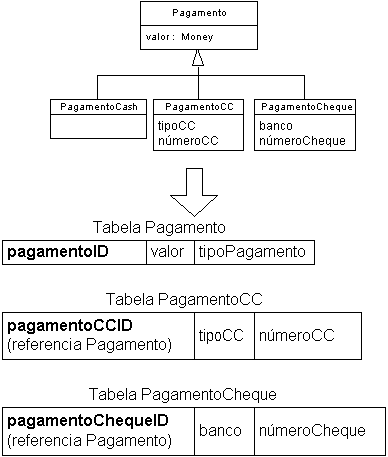
- Empurrar atributos da superclasse para baixo
- Elimine a superclasse e duplique seus atributos para cada subclasse
- Uma única tabela contém todos os dados de um objeto (não há necessidade de join para
reconstituir um objeto)
- Desvantagens
- Introduz redundância no esquema
- Poderá ser necessário pesquisar várias tabelas para achar um objeto
- Se vários níveis de hierarquia estiverem envolvidos, a estrutura da generalização
(herança) é perdida
- Exemplo:
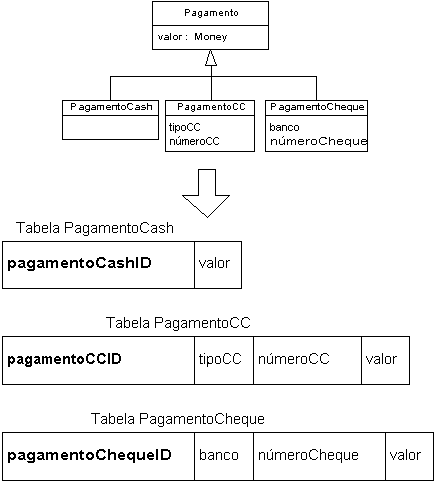
- Empurrar atributos da subclasse para cima
- Neste caso, as subclasses são eliminadas e todos seus atributos
migram para a tabela da superclasse
- Atributo desnecessários para certos objetos são nulos
- Essa alternativa viola a segunda forma normal porque alguns
atributos não dependem completamente da chave primária
- Exemplo:
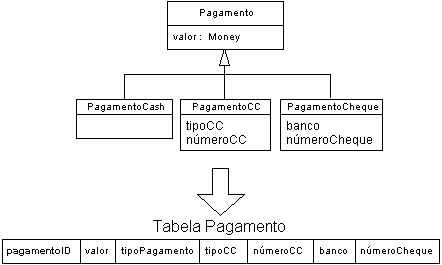
- Abordagem híbrida
- Empurrar os atributos da superclasse para baixo mas manter a
tabela da superclasse para navegar nas subclasses
- Exemplo:
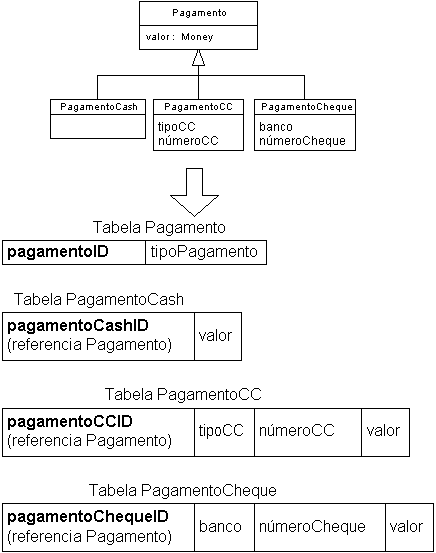
- Tabela de generalização
- Semelhante ao mapeamento recomendado (tabelas para superclasse e subclasses) mas
adicionando uma tabela de generalização que amarra a chave primária da superclasse à
chave primária da subclasse
- A chave primária das subclasses é a chave "natural" da tabela e não mais a
mesma da superclasse como no mapeamento recomendo inicial
- Recomendado
- Usar o mapeamento recomendado acima (tabelas distintas para superclasse e subclasses)
- Cada classe UML é mapeada para uma tabela
- Cada atributo da clase é uma coluna da tabela
- O tipo do atributo é mapeado para um tipo da coluna, de acordo com regras de
transformação de tipos
- Se o atributo tem o tag UML {nullable}, a coluna tem constraint NULL; caso contrário,
tem constraint NOT NULL
- Se o atributo UML tem um inicializador, adicionar a cláusula DEFAULT à coluna
- Para cada classe sem generalização (é raiz de hierarquia ou não participa de
hierarquia) e com identidade baseada na existência, criar uma chave primária inteira;
com identidade baseada em valor, adicionar as colunas com tag UML {OID} ao constraint
PRIMARY KEY
- Para subclasses com uma única superclasse com chave primária de uma coluna, adicionar
a chave da superclasse ao constraint PRIMARY KEY e adicionar uma cláusula REFERENCES para
relacionar a coluna (chave estrangeira) à chave primária da superclasse
- Para subclasses com uma única superclasse com chave primária de várias colunas, use
constraints de tabela PRIMARY KEY e FOREIGN KEY em vez do constraint de coluna do item
anterior
- Para herança múltipla, adicione uma coluna na subclasse para cada chave primária de
cada superclasse; adicione um constraint de tabela FOREIGN KEY com todas essas colunas
(que referenciam chaves primárias das superclasses)
- Para classes de associação, adicione uma coluna para a chave primária de cada classe
participando da associação; use um constraint FOREIGN KEY
- Para tags UML {alternate OID}, adicione as colunas envolvidas ao constraint UNIQUE
- Adicione CHECK para cada constraint explícito
- Crie tabelas para as associações que não usam chaves estrangeiras embutidas
(muitos-para-muitos, ternárias, ...), e use constraint de tabela FOREIGN KEY
- Para agregações, use a opção ON DELETE CASCADE, ON UPDATE CASCADE na tabela
agregadora
proj1-9 programa anterior