Análise de Algoritmos de Ordenação
Formalmente, o problema da ordenação pode ser assim definido:
Em geral, consideramos a seqüência de entrada como um array de ![]() elementos.
elementos.
![\begin{algorithmic}
\STATE {\bf InsertionSort(A)}
\STATE
\FOR{$j \leftarrow 2$\ ...
...1$ \ENDWHILE
\STATE $A[i + 1] \leftarrow chave$\ENDFOR
\STATE
\end{algorithmic}](img5.png)
A análise do algoritmo InsertionSort é muito simples e pode ser efetuada com as regras básicas para análise de algoritmos simples, apresentadas anteriormente.
É trivial observar que o algoritmo é ![]() .
.
Alguns algoritmos clássicos que utilizam recursão se baseiam na estratégia de divisão-e-conquista que estudaremos mais adiante. A solução, nestes casos, pode ser definida em 3 passos:
Diferentes algoritmos recursivos foram definidos. Algumas soluções concentram os esforços na fase de quebrar o tamanho do problema, fazendo com que a fase de combinação das partes ordenadas seja simples. Outras soluções definem uma forma simples de quebrar o problema, deixando o maior esforço para a combinação dos resultados.
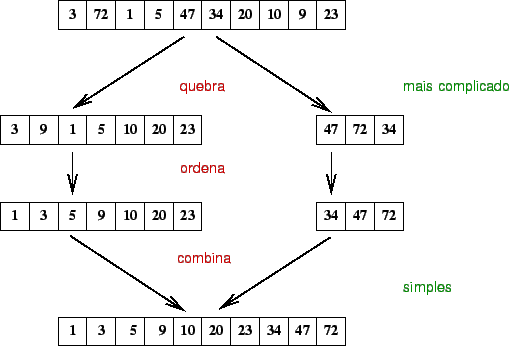
O mergesort faz parte dos algoritmos em que a partição é simples e a combinação é mais trabalhosa.
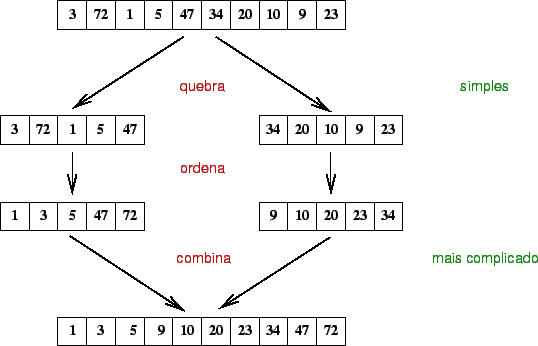
O algoritmo:

A análise do MergeSort requer a resolução de uma relação
de recorrência. Para simplificação mas, sem perda de generalidade, vamos
considerar ![]() como sendo uma potência de 2. Isso possibilita sempre dividir
em duas partes iguais com um número par de elementos. Para
como sendo uma potência de 2. Isso possibilita sempre dividir
em duas partes iguais com um número par de elementos. Para ![]() , o tempo
do mergesort é constante. Nos outros casos, o tempo de execução do algoritmo
é o tempo de execução de duas chamadas recursivas com
, o tempo
do mergesort é constante. Nos outros casos, o tempo de execução do algoritmo
é o tempo de execução de duas chamadas recursivas com ![]() elementos,
mais o tempo de intercalação que é linear.
elementos,
mais o tempo de intercalação que é linear.
A relação de recorrência é:
Resolvendo a relação de recorrência temos:

Como o MergeSort, o QuickSort também é um algoritmo que utiliza a estratégia de divisão-e-conquista. Entretato, ao contrário do MergeSort, a parte mais complicada é a quebra ou partição da seqüência de entrada. A combinação das partes é trivial.
O QuickSort é talvez o algoritmo de ordenação mais usado. É fácil de implementar e muito rápido na prática.
O algoritmo:

A função de particionamento pode ser definida de diferentes formas. Por exemplo:
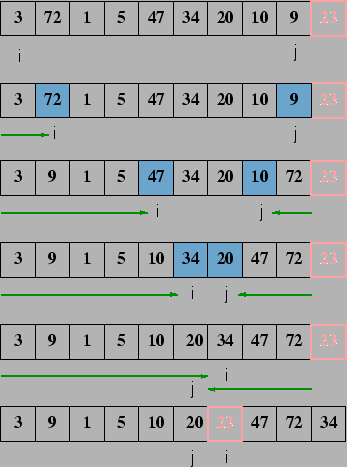
A análise do QuickSort também requer a resolução de uma relação de recorrência. Como nem sempre os dados são divididos em duas metades de igual número de elementos, é necessário fazer análise para o melhor caso, pior caso e o caso médio.
Assumindo que o tempo de partição é ![]() , e que a posição final
do pivô é
, e que a posição final
do pivô é ![]() , a relação de recorrência é
, a relação de recorrência é
Algumas considerações:
O Melhor Caso
O melhor caso é quando o pivô sempre fica no meio. Nesse caso, podemos
considerar que as duas partes têm a metade de elementos do problema original.
Na verdade, estamos super-estimando um pouco mas isso é perfeitamente
aceitável pois estamos interessados no big-oh. Logo,
![]() e, como vimos no mergesort, isso indica
e, como vimos no mergesort, isso indica
![]() .
.
O Pior Caso
No pior caso, o pivô está sempre na primeira ou última posição:
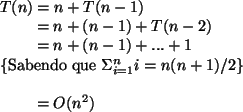
Caso Médio

Todos os algoritmos de ordenação que estudamos até agora
utilizam comparação de elementos. Em uma ordenação por comparação,
informação sobre a ordem relativa de dois elementos ![]() e
e ![]() em
uma sequência é obtida utilizando testes de comparação:
em
uma sequência é obtida utilizando testes de comparação:
![]() ,
, ![]() ,
, ![]() ,
, ![]() ou
ou
![]() .
.
É possível usar árvores de decisão para visualizar ordenação por comparação.
A figura a seguir mostra um exemplo de árvore de decisão para ordenação de uma entrada de seqüência de 3 elementos.
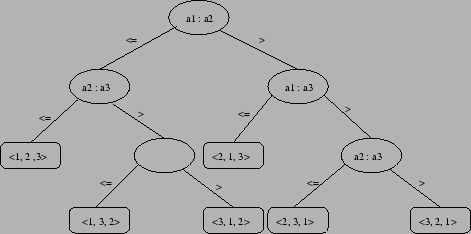
As folhas desta árvore indica uma possível ordenação para
os elementos. O número de permutações possível é ![]() .
.
Prova de um limite inferior para o pior caso:
Para definir este limite inferior, vamos utilizar algumas propriedades de árvore:
O caminho mais longo da raiz de uma árvore de decisão para qualquer uma de suas folhas representa o pior caso do número de comprações que o algoritmo de comparação executa (a maior profundidade de todas as folhas).

Esse algoritmo considera que cada um dos ![]() elementos a serem ordenados é
um inteiro entre
elementos a serem ordenados é
um inteiro entre ![]() e
e ![]() . A idéia básica deste algoritmo é determinar para
cada elemento de entrada
. A idéia básica deste algoritmo é determinar para
cada elemento de entrada ![]() , o número de elementos menores do que
, o número de elementos menores do que ![]() . Desta
forma é possível posicionar
. Desta
forma é possível posicionar ![]() no array de saída.
no array de saída.
Esse algoritmo requer dois arrays auxiliares: ![]() que corresponde
ao array com a saída ordenada e
que corresponde
ao array com a saída ordenada e ![]() que provê armazenamento
temporário.
que provê armazenamento
temporário.
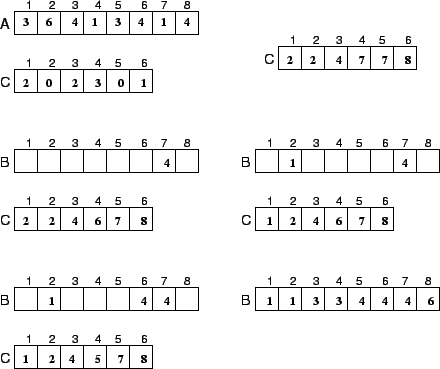
O algoritmo:
![\begin{algorithmic}
\STATE {\bf Counting-Sort(A, B, k)}
\STATE
\FOR{$i \leftarr...
...leftarrow A[j]$ \STATE $C[A[j]] \leftarrow C[A[j]] - 1$\ENDFOR
\end{algorithmic}](img46.png)
A análise deste algoritmo é trivial. O primeiro e o terceiro
laços correspondem a ![]() , enquanto o segundo e o quarto laços
são
, enquanto o segundo e o quarto laços
são ![]() . O tempo total é, portanto,
. O tempo total é, portanto, ![]() .
.
Na prática, utiliza-se CountingSort quando ![]() , proporcionando
um tempo d execução
, proporcionando
um tempo d execução ![]() .
.
Um exemplo: